
半扩散工作室 #19: 生成式人工智能概述Part 1

第 1 章 行业发展历程与现状
生成式人工智能(GenerativeAI, 后简称GenAI)是指基于人类提供的意图或指令,使用先进的生成性人工智能技术生成的内容。技术上,生成过程通常分成两个步骤:从人类指令(通常称作提示词prompt)中提取意图信息, 然后根据这些意图信息生成相应的内容。与人类作者创作的内容不同,GenAI能够在短时间内自动化地创造大量内容。近年来,基于更大数据集、更强大的基础模型架构以及更强的计算能力的GenAI模型,已成为AI技术发展的核心突破。许多人相信GenAI代表了AI发展的新时代,它将改变人类的生活方式。
目前,GenAI技术的成熟和成功主要体现在两个方向:
第一,语言模型。代表性的例子是OpenAI开发的ChatGPT[1], 它能够高效地理解人类语言并与人类对话。
第二,基于文字描述的图片生成。最具代表性的例子包括MidJourney和OpenAI的DALL·E 3。他们能够根据例如“一名宇航员骑马,真实照片风格”的文字描述生成独特且高质量的图片。
1.1 技术的发展历史
GenAI模型在人工智能领域拥有悠长的历史,可追溯至1950年代的隐式马尔科夫模型(Hidden Markov Models, HMMs)以及高斯混合模型(Gaussian Mixture Models, GMMs)。 这些模型能够生成语言和时间序列数据。
在深度学习早期,GenAI模型在不同领域互相独立。在自然语言处理(Natural Language Processing, 后简称NLP)领域,生成句子的传统方式是使用N-gram模型来学习单词的分 布,并搜索最佳的句子。然而,这种方法无法有效地拓展至长句子。为了解决这个问题, 循环神经网络(RecurrentNeuralNetworks, 后简称RNN)被引入来建模句子中更长的依赖关系。1997年,Hochreiter和Schmidhuber提出了长短时记忆网络(Long Short-Term Memory, 后简称LSTM),解决了RNN的梯度消失/梯度爆炸的问题,使得神经网络可以更好地 处理长文本内容。同时,在计算机视觉(ComputerVision, 后简称CV)领域, 在基于深度学习的方法之前,传统的图片生成算法如texture synthesis和texture mapping 的方法,基于人工设计的特征,无法生成复杂图片。在 2014 年,Ian Goodfellow 提出的对抗生成网络(Generative Adversarial Network,简称 GANs)成为里程碑式的进展。GANs 基于卷积神经网络(Convoluted Neural Networks, CNNs), 将两个神经网络进行对抗,即生成器与鉴别器不断对抗进行模型训练,生成更高质量的图片。之后,Variational Autoencoders(VAEs) 和其他比如扩散生成模型(Diffusion Generative Models)等方法被发明,使得可以更精细地控制图片生成过程,从而生成更高质量的图片。
在 2017 年,谷歌的研究团队(Vaswani 等)在一篇题为《注意力就是你所需要的一切》 [2]的论文中针对NLP的任务提出了Transformer架构,之后Transformer被用于CV,并成 为许多不同领域的生成模型的主流框架。在大语言模型(Large Language Models, 后简称LLM)领域,比如BERT和Generative Pre-training(GPT)都采用了Transformer架构。
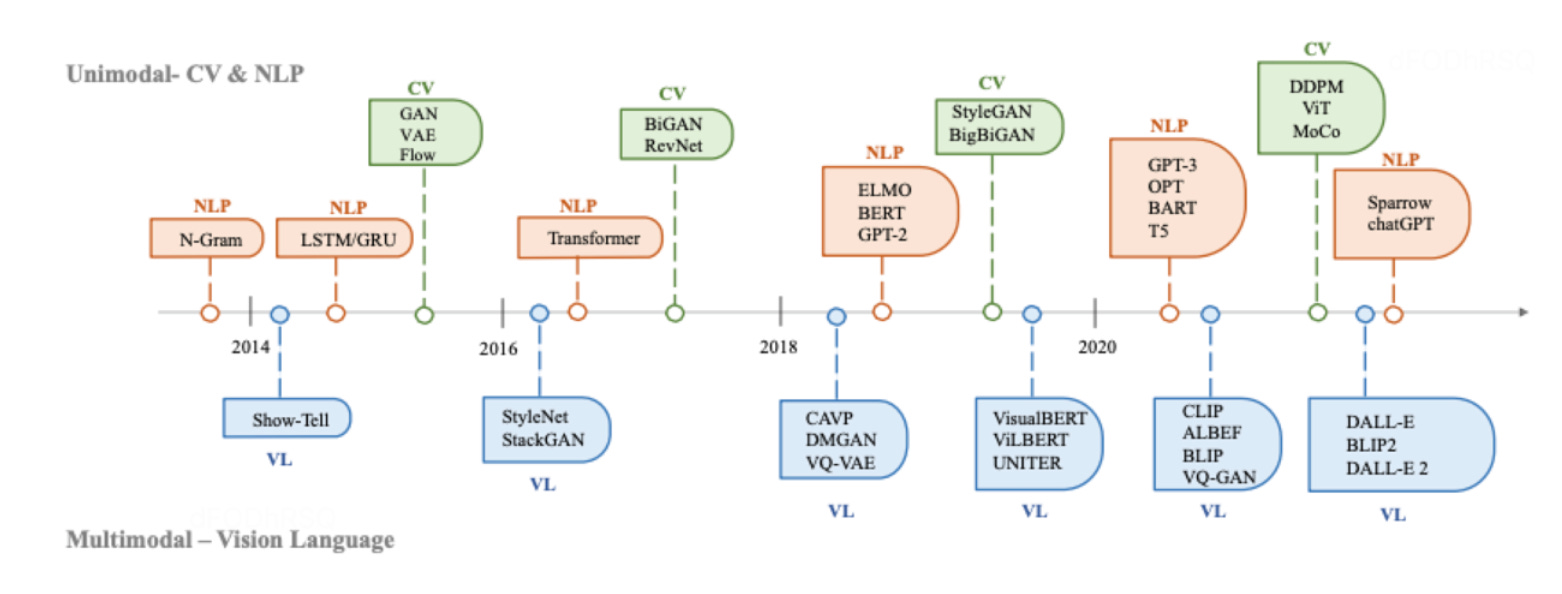
图一 GenAI在 CV(Computer Vision),NLP(Natural Language Processing)和VL(Vision Language)的发展历史
1.2 GenAI基础
1.2.1 基础模型
Transformer 是众多领先模型的核心架构,例如GPT-3、DALL·E 2和Codex。它最初被提出是为了解决传统模型如 RNN 在处理可变长度序列和上下文意识方面的局限性。Transformer 架构主要基于自注意力(Self Attention)机制,使模型能够关注输入序列中的 不同部分。Transformer 由编码器和解码器组成。编码器接收输入序列并生成隐藏表示,而 解码器则接收隐藏表示并生成输出序列。编码器和解码器的每一层都由多头注意力(Multi- Head Attention)和前馈神经网络(Feed-Forward Network)组成。多头注意力是Transformer的核心组成部分,它学会根据 token 的相关性分配不同的权重。这种信息路由方法使模型更擅长处理长期依赖性,从而提高了在广泛的自然语言处理任务中的性能。Transformer 的 另一个优势是其架构使其高度可并行化,并允许数据超越归纳偏见。这种特性使得 Transformer非常适合大规模预训练,使基于 Transformer 的模型能够适应不同的下游任务。
在生成式语言模型领域,预训练是非常重要的一环。基于 Transformer 的预训练语言 模型通常分为两类:自回归语言建模(autoregressive language modeling)和掩码语言建模 (masked language modeling)。GPT-3 最著名的自回归语言模型之一; 掩码语言模型则是 在给定一个由几个 token 组成的句子,在上下文信息情况下预测掩码 token 的概率。BERT 是其中最著名的例子。随着预训练数据量大幅增加,模型的能力也显著增强。比如 GPT-3 的主要框架和 GPT-2 一致,但是预训练数据从 WebText(38GB)到 CommonCrawl(过滤后570GB), 基础模型的参数量从 15 亿增加到 1750 亿。所以,GPT-3 具备了在不同任务上比 GPT-2 更强大的泛化的能力。
在图像生成领域,扩散模型(Diffusion Models)是在 2015 年的 Deep Unsupervised Learning using Nonequilibrium Thermodynamics[3]文章中提出。Diffusion 模型分为两个部分:前向过程 (Forward Diffusion Process)在图片中添加噪声,这个过程用于训练阶段;反向过程(Reverse Diffusion Process)去除图片中的噪声。这种由“增加噪声”到“去除噪声”的过程,使得扩散模型在图像生成领域表现出了独特的效果和应用潜力。
1.2.2 来自人类反馈的强化学习
来自人类反馈的强化学习(Reinforcement Learning from Human Feedback,后简称 RLHF),尽管在大规模数据上进行了训练,人工智能内容生成(AIGC)可能不总是能产生与用户意图一致的输出,这包括考虑到有用性和真实性。为了更好地使 AIGC 的输出与人 类偏好一致,已经将RLHF应用于微调各种应用中的模型,如 InstructGPT 和 ChatGPT。 通常,RLHF的整个流程包括以下三个步骤:预训练、奖励学习和使用强化学习进行微调。 首先,将一个在大规模数据集上预训练的语言模型作为初始语言模型。由于给出的(提示词-答案)对可能不符合人类目的,所以在第二步中训练一个奖励模型来编码多样化和复杂的人类偏好。具体来说,给定相同的提示词,不同生成的答案由人类以成对方式进行评估。成对比较关系稍后使用如ELO等算法转换为奖励数值。在最后一步中,使用强化学习对语言模型进行微调,以最大化学习到的奖励函数。为了稳定强化学习训练,常用邻近策略优化(Proximal Policy Optimization,简称 PPO)作为强化学习算法。在每一轮强化学习训练中,都会考虑一个经验估计的惩罚项,以防止模型输出一些奇特的内容来欺骗奖励模型。
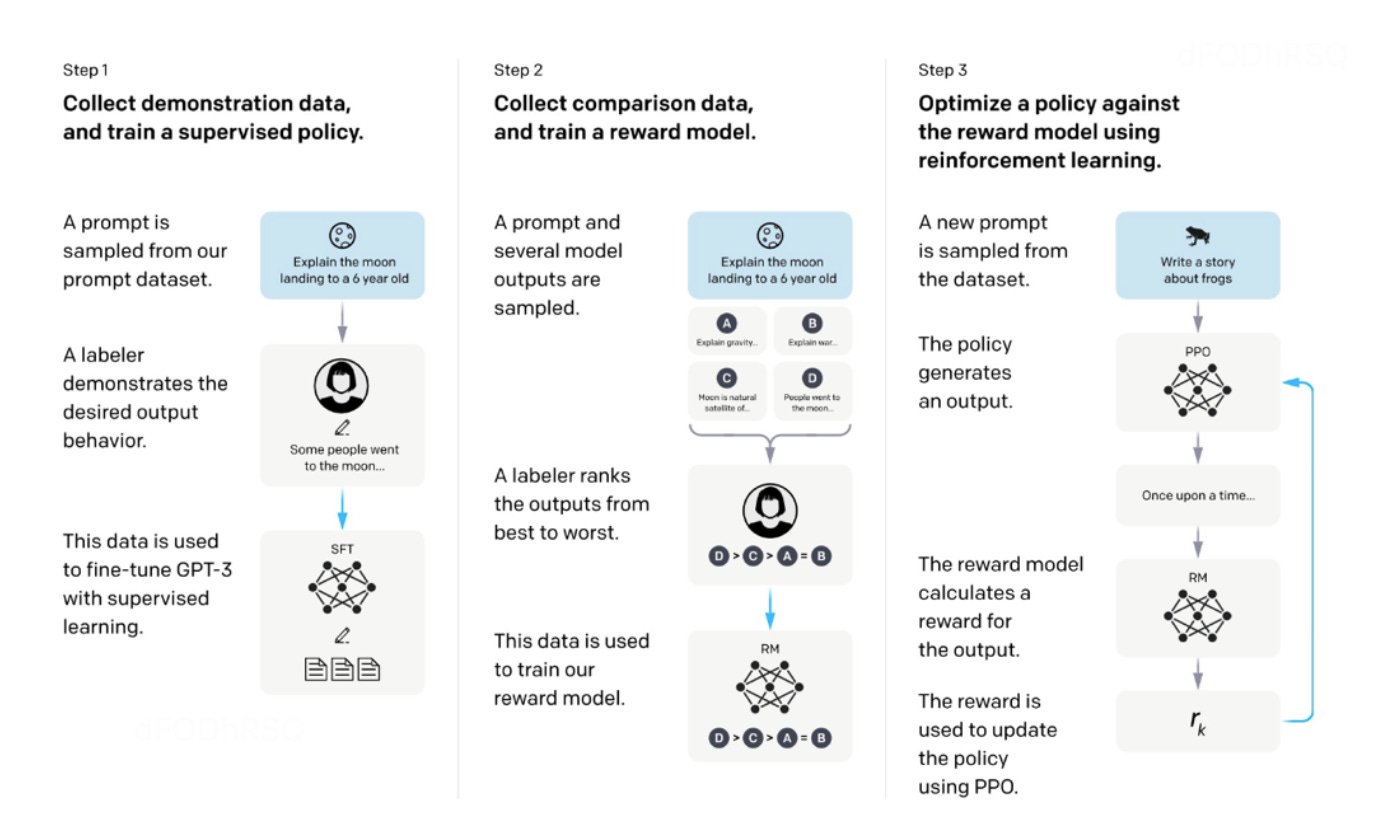
图二 InstructGPT 的架构。首先,收集由人类标注员提供的示范数据,并用这些数据来微调GPT-3。然后,从语言模型中抽取提示及其相应的答案,人类标注员将对这些答案进行从最好到最差的排名。这些数据被用来训练奖励模型。最后,有了训练好的奖励模型,语言模型可以根据人类标注员的偏好进行优化。
第2章 技术特点
GenAI技术之所以取得成功,主要归功于其以下两个显著特点:
2.1 通用性
GenAI的最显著特点在于其通用性,它对用户的使用方式和应用场景没有特定的限制和要求。正因如此,GenAI技术成为了类似于电力、微处理器、个人电脑、互联网和手机这样的通用技术,对提升生产力具有重大的影响和潜力。这种广泛的应用性使得GenAI不仅仅是一项技术创新,更将成为未来生产和日常生活中不可或缺的基础设施。
2.2 计算硬件及服务
近年来,计算相关硬件的重大进步大幅促进了大规模模型的训练。过去,使用CPU训练大型神经网络可能需要几天甚至几周的时间。然而,随着更强大的计算资源的出现,这一过程的速度提高了数个数量级。例如,NVIDIA的A100 GPU在BERT-large推理中比V100快七倍,比T42 快11倍。此外,谷歌专为深度学习设计的张量处理单元(Tensor Procesing Units,简称TPUs)提供的计算性能甚至高于当前一代A100GPUs。这种计算能力的快速进步显著提高了AI模型训练的效率,并为开发大型和复杂模型开辟了新的可能性。
此外,分布式训练至关重要。与传统的机器学习模型训练在单一机器上完成不同,分布式训练将计算任务分散到多个处理器或机器上,使得训练过程能够更快地完成。这不仅提高了训练效率,还降低了单个设备的负载。同时,为了支持这种分布式训练,出现了多种专门的工具和框架,如TensorFlow、PyTorch等,这些工具不仅提供了必要的技术支持,还使得分布式训练变得更加易于实施和优化。通过这些工具,研究人员和开发者能够更有效地协同工作,推动GenAI技术的快速进步。
